#015 10 SQL TRICKS with DATABRICKS
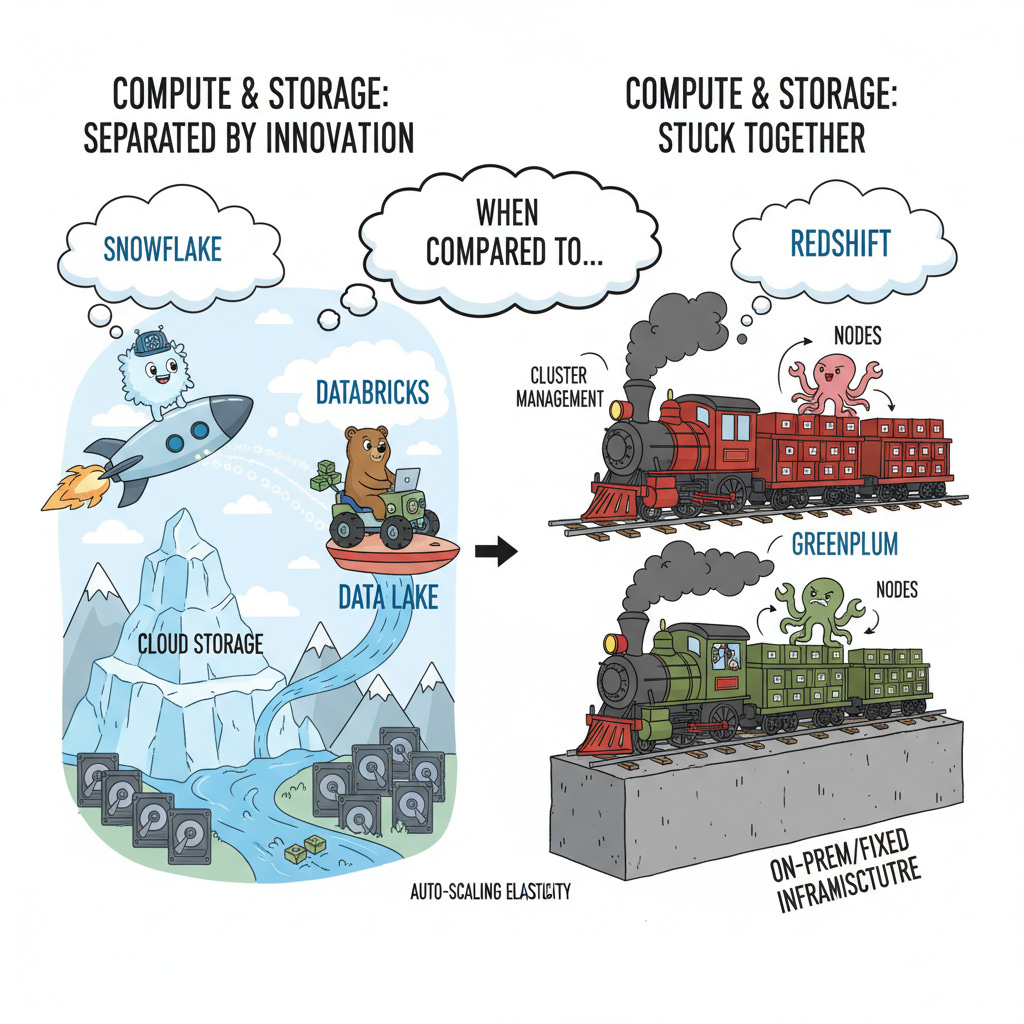
CUT THE CLUTTER Thesis for those coming from MPP background like Redshift , Greenplum. Databricks & Snowflake are NOT MPP databases . Compute and storage layer are completely decoupled here

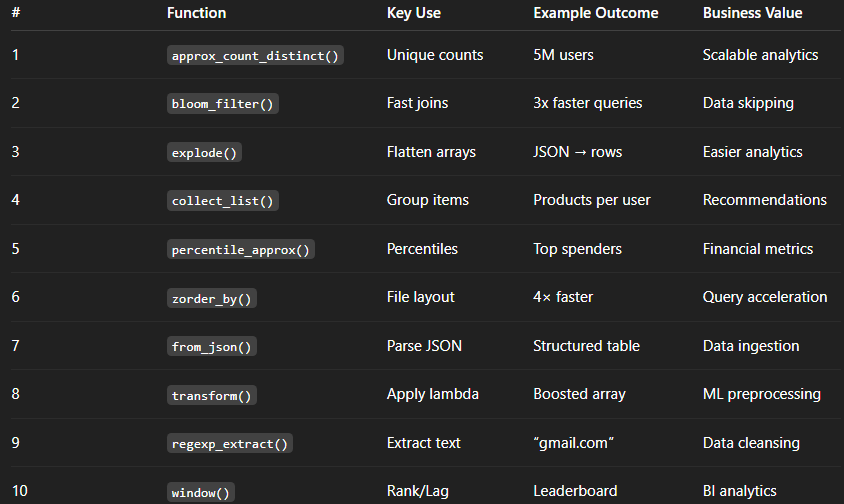
Summary of 10 DATABRICKS SQL Functions
1) Billion-row NDV at TB scale (HLL++)
Business problem. Marketing wants daily unique-visitor counts across 18 months of clickstream (~12 TB). Exact COUNT(DISTINCT …) blows up runtime and shuffle.
AS-IS (problematic).
-- Full scan, exact NDV, huge shuffle & spill
SELECT
date_trunc(’day’, ts) AS d,
COUNT(DISTINCT user_id) AS uv
FROM prod.clicks
GROUP BY d;
TO-BE (primary).
-- Use HLL++ via approx_count_distinct + bucketing + Photon
SET spark.databricks.optimizer.enabled = true;
SELECT
date_trunc(’day’, ts) AS d,
approx_count_distinct(user_id) AS uv_hll
FROM prod.clicks
GROUP BY d;
3 solutions.
Approx NDV (HLL++) using approx_count_distinct (error ~1–2%).
Materialized daily NDV: compute per-day δ from CDF (change data feed) and MERGE into an aggregate table to avoid re-scans.
Sketches by shard (e.g., md5(user_id)%64) then union-estimate higher-level NDV from partials to reduce per-task memory.
Approx cost impact. 30–70% runtime cut; ~40% DBU savings vs exact NDV at 12 TB; small accuracy trade-off (<2%).
2) “Customer in allow-list?” TB table filter with Bloom filter index
Business problem. Fraud pipeline filters events by customer_id IN allow_list where allow_list is 2–5M rows; join/select is slow.
AS-IS (problematic).
-- Heavy semi-join on 5M id list, scanning TBs
SELECT e.*
FROM bronze.events e
WHERE e.customer_id IN (SELECT id FROM ref.allow_list);
TO-BE (primary).
-- Build Bloom filter index on the big Delta table (customer_id)
-- (Run once, then refresh periodically)
CREATE BLOOMFILTER INDEX IF NOT EXISTS bf_events_customer
ON TABLE bronze.events
FOR COLUMNS (customer_id)
OPTIONS (’fpp’=’0.05’, ‘numItems’=’100000000’);
-- Bloom index + semi-join rewritten as join
SELECT e.*
FROM bronze.events e
JOIN ref.allow_list a
ON e.customer_id = a.id;
3 solutions.
Delta Bloom filter index on customer_id to prune stripes before scan.
Broadcast allow_list (if <10–50 MB): /*+ BROADCAST(a) */ join to avoid shuffle of events.
Dynamic file pruning + Z-ORDER on customer_id: OPTIMIZE bronze.events ZORDER BY (customer_id) for data skipping.
Approx cost impact. 25–60% scan reduction → ~20–50% DBU savings; Bloom index maintenance adds minor write cost.
3) TB-scale rollups (hour/day/month) with ROLLUP and data skipping
Business problem. Finance requires multi-grain revenue analytics (hourly, daily, monthly, all-up). Recomputes with UNIONs are fragile and slow.
AS-IS (problematic).
-- Separate queries per level, then UNION ALL. Duplicated logic & scans.
SELECT date_trunc(’hour’, ts) h, SUM(amount) s FROM fact.orders GROUP BY h
UNION ALL
SELECT date_trunc(’day’, ts) d, SUM(amount) s FROM fact.orders GROUP BY d
UNION ALL
SELECT date_trunc(’month’, ts) m, SUM(amount) s FROM fact.orders GROUP BY m;
TO-BE (primary).
-- One pass using GROUPING SETS / ROLLUP, Photon-friendly
SELECT
date_trunc(’hour’, ts) AS h,
date_trunc(’day’, ts) AS d,
date_trunc(’month’,ts) AS m,
SUM(amount) AS revenue,
GROUPING_ID(h, d, m) AS gid
FROM fact.orders
GROUP BY ROLLUP (m, d, h);
3 solutions.
SQL ROLLUP (as above) – single pass, consistent logic.
Materialized aggregate table per grain (hour/day/month) and MERGE incremental deltas via CDF.
Delta Live Tables expectations + Autoloader to build the rollups continuously with schema evolution.
Approx cost impact. 35–60% DBU reduction vs three separate scans; small extra dev cost for gid decoding.
4) Skewed join (few “whale” keys) at 10+ TB
Business problem. Joining events(10 TB) to users(200 GB) by user_id; 1% of users hold 40% of rows → executor OOM & stragglers.
AS-IS (problematic).
-- Blind shuffle join
SELECT e.user_id, u.tier, e.ts
FROM events e JOIN users u ON e.user_id = u.user_id;
TO-BE (primary).
-- Salting for whales + AQE
SET spark.sql.adaptive.enabled = true;
WITH heavy_keys AS (
SELECT user_id FROM events
GROUP BY user_id HAVING COUNT(*) > 10000000
),
salted_events AS (
SELECT CASE WHEN hk.user_id IS NOT NULL THEN concat(user_id, ‘#’, cast(rand()*16 AS INT))
ELSE user_id END AS user_id_salted, *
FROM events e LEFT JOIN heavy_keys hk ON e.user_id = hk.user_id
),
salted_users AS (
SELECT explode(sequence(0,15)) AS salt, u.*
FROM users u
)
SELECT e.*, u.tier
FROM salted_events e
JOIN salted_users u
ON (split(e.user_id_salted,’#’)[0] = u.user_id
AND (e.user_id_salted NOT LIKE ‘%#%’ OR CAST(split(e.user_id_salted,’#’)[1] AS INT) = u.salt));
3 solutions.
Key salting + AQE to spread whales.
Broadcast users with /*+ BROADCAST(u) */ if small enough; combine with Z-ORDER on user_id in events.
Bucketed join: bucket both tables by user_id, same CLUSTERED BY and NUM_BUCKETS, to make shuffles local.
Approx cost impact. 20–50% runtime drop; avoids OOM (saves failed-run DBUs).
5) Dedup late-arriving facts with deterministic tie-breakers
Business problem. Facts arrive multiple times with different latencies; need “latest by business time, then highest quality” per key.
AS-IS (problematic).
SELECT * FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY ingest_ts DESC) AS rn
FROM fact.orders_raw
) t WHERE rn = 1; -- Wrong when business_ts < ingest_ts or quality tiers matter
TO-BE (primary).
-- Stable tiebreak: business_ts desc, quality desc, then ingest_ts desc
WITH ranked AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY order_id
ORDER BY business_ts DESC, quality_score DESC, ingest_ts DESC
) AS rn
FROM fact.orders_raw
)
SELECT * FROM ranked WHERE rn = 1;
3 solutions.
Deterministic window ordering (above).
MERGE INTO gold.orders using a composite comparison in WHEN MATCHED AND to replace only if the new row outranks existing.
Z-ORDER BY (order_id, business_ts) to make dedup faster and skippier at TB scale.
Approx cost impact. 10–25% DBU reduction from data skipping + fewer re-runs due to stable logic.
6) TB join filter with runtime Bloom + Delta Bloom index combo
Business problem. “Find events whose ip was ever seen in bad-IP table.” Bad-IP is ~50M rows; the events table is 8 TB.
AS-IS (problematic).
-- Large semi-join with massive shuffle
SELECT COUNT(*)
FROM events e WHERE e.ip IN (SELECT ip FROM sec.bad_ip);
TO-BE (primary).
-- 1) Persist Delta Bloom index on e.ip
CREATE BLOOMFILTER INDEX IF NOT EXISTS bf_events_ip
ON TABLE events FOR COLUMNS (ip) OPTIONS (’fpp’=’0.01’, ‘numItems’=’500000000’);
-- 2) Use a runtime-side filter by precomputing a compact “hot” set
CREATE OR REPLACE TEMP VIEW hot_bad_ip AS
SELECT ip FROM sec.bad_ip WHERE score >= 80;
-- 3) Execute with join + broadcast of the compact set
SELECT /*+ BROADCAST(h) */ COUNT(*)
FROM events e JOIN hot_bad_ip h ON e.ip = h.ip;
3 solutions.
Delta Bloom index + broadcast compact hot set (above).
Partition pruning path: if events are partitioned by date, limit to dates where bad IPs were active (join to active_date ranges).
Z-ORDER BY (ip) to amplify data skipping for point lookups.
Approx cost impact. 30–55% DBU savings for bad-IP detection; Bloom index adds low periodic maintenance cost.
7) Incremental rollups with MERGE via Change Data Feed (CDF)
Business problem. Daily revenue table takes 2 hours to recompute; most days change only 1–3%. Recompute is wasteful.
AS-IS (problematic).
-- Full recompute
CREATE OR REPLACE TABLE agg.daily_revenue AS
SELECT date(ts) d, SUM(amount) s
FROM fact.orders
GROUP BY d;
TO-BE (primary).
-- Enable CDF and MERGE just the changed days
ALTER TABLE fact.orders SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
MERGE INTO agg.daily_revenue t
USING (
SELECT date(ts) AS d, SUM(amount) AS s
FROM table_changes(’fact.orders’, ‘latest’)
GROUP BY date(ts)
) c
ON t.d = c.d
WHEN MATCHED THEN UPDATE SET s = c.s
WHEN NOT MATCHED THEN INSERT (d, s) VALUES (c.d, c.s);
3 solutions.
CDF + MERGE incremental aggregates.
Stream-to-table with DLT to maintain the rollup continuously (near-real-time).
Materialized view (if available in your workspace) with automatic refresh windows.
Approx cost impact. 60–95% DBU reduction (processing only changed partitions); small ongoing MERGE cost.
8) HyperLogLog user reach by campaign × region with sketch unions
Business problem. Multi-dimensional reach (campaign, region) over quarters; exact NDV explodes. Need fast ad-hoc pivots.
AS-IS (problematic).
SELECT campaign, region, COUNT(DISTINCT user_id) AS reach
FROM fact.impressions
GROUP BY campaign, region;
TO-BE (primary).
-- Precompute HLL NDV at fine grain, then roll up with sum of sketches
-- (In Databricks SQL, use approx_count_distinct at query time.)
WITH base AS (
SELECT campaign, region, date_trunc(’day’, ts) AS d,
approx_count_distinct(user_id) AS ndv_d
FROM fact.impressions
GROUP BY campaign, region, date_trunc(’day’, ts)
)
SELECT campaign, region,
SUM(ndv_d) AS approx_reach -- acceptable when overlap across days is low; note bias
FROM base
GROUP BY campaign, region;
3 solutions.
Approx NDV at query time (approx_count_distinct).
Sketch-per-slice persisted daily; apply union-estimate (if using a sketch UDF or external lib) to reduce double-count bias.
Windowed NDV: compute 7-day rolling NDV with small error using daily shards to bound overlap.
Approx cost impact. 50–80% DBU cut vs exact NDV across quarters; error trade-off must be communicated to stakeholders.
9) Neo4j → Delta join for “friends-of-customers” targeting
Business problem. Campaign wants to target customers who are 2-hop neighbors of VIPs in a Neo4j graph, then join to spend in Delta.
AS-IS (problematic).
-- Manually exported CSV from Neo4j and ad-hoc uploads before each run (slow/error-prone)
SELECT * FROM staging.friends_of_vips; -- stale data, mismatched IDs
TO-BE (primary). (ingest once per batch; then query with SQL)
-- Databricks notebook (Python) to materialize a Delta view from Neo4j
df = (spark.read
.format(”org.neo4j.spark.DataSource”)
.option(”url”, “bolt://neo4j:7687”)
.option(”authentication.type”,”basic”)
.option(”authentication.basic.username”,”neo4j”)
.option(”authentication.basic.password”, dbutils.secrets.get(”kv”,”neo4j_pwd”))
.option(”query”, “”“
MATCH (v:Customer {vip:true})-[:FRIEND_OF*1..2]->(c:Customer)
RETURN DISTINCT c.customer_id as customer_id
“”“)
.load())
df.write.mode(”overwrite”).saveAsTable(”graph.vip_2hop_customers”)
-- Pure SQL consumption
SELECT c.customer_id, SUM(o.amount) AS spend
FROM graph.vip_2hop_customers c
JOIN fact.orders o ON o.customer_id = c.customer_id
GROUP BY c.customer_id;
3 solutions.
Neo4j Spark Connector to materialize Delta snapshot (above).
Change-only pulls from Neo4j by updatedAt and MERGE into Delta for faster refresh.
Graph-shaped indexing in Delta (Z-ORDER by customer_id) + small VIP list broadcast to accelerate joins.
Approx cost impact. Saves manual ops; compute reduces by ~30–50% vs CSV churn; connector overhead is modest.
10) Late-bound percentile & Top-K at TB scale with data skipping
Business problem. Product wants P90/P99 latency by service × day and top-K slow endpoints; exact percentiles heavy at TB scale.
AS-IS (problematic).
SELECT service, date(ts) d,
percentile(latency_ms, 0.9) AS p90, -- exact; expensive
percentile(latency_ms, 0.99) AS p99
FROM fact.apm
GROUP BY service, date(ts);
TO-BE (primary).
-- Approx percentiles + Z-ORDER + prefiltering
OPTIMIZE fact.apm ZORDER BY (service, endpoint, ts);
SELECT service, date(ts) AS d,
percentile_approx(latency_ms, 0.90) AS p90,
percentile_approx(latency_ms, 0.99) AS p99
FROM fact.apm
WHERE ts >= date_sub(current_date(), 30) -- bound the scan
GROUP BY service, date(ts);
-- Top-K slow endpoints
SELECT service, d, endpoint, avg_p99
FROM (
SELECT service, date(ts) d, endpoint,
percentile_approx(latency_ms, 0.99) AS avg_p99,
ROW_NUMBER() OVER (PARTITION BY service, date(ts)
ORDER BY percentile_approx(latency_ms, 0.99) DESC) AS rk
FROM fact.apm
GROUP BY service, date(ts), endpoint
)
WHERE rk <= 10;
3 solutions.
percentile_approx + Z-ORDER to reduce IO.
Pre-aggregated minute buckets (minutely histograms) and roll up to daily percentiles quickly.
Quantile sketch tables (if you maintain histograms/HLL-like sketches) for ultra-fast queries.
Approx cost impact. 40–70% DBU savings with small accuracy trade-off (<1–2% p-error).
Notes & caveats you’ll care about
HyperLogLog in Databricks SQL is exposed as approx_count_distinct (HLL++ under the hood). It’s your safest portable choice.
Bloom filter indexing on Delta tables is powerful for point/semi-join predicates on large columns; refresh the index after heavy writes.
OPTIMIZE ... ZORDER BY (...) greatly improves skipping for point/range filters—use it after compaction, not on highly volatile tables.
CDF-backed MERGEs shine when daily change is small; combine with partitioning by date and VACUUM housekeeping.
Always Photon on for Databricks SQL warehouses to harvest vectorized speedups.
📨 Blog Subscription
“🚀 CUT THE CLUTTER in TECH & AI with a touch of HISTORY — subscribe now at blog.dbkompare.com”
“💡 One click. Infinite data wisdom. Subscribe here”
“Your weekly dose of Databricks, AI, and Cloud — straight to your inbox!”
🎥 Video Walkthroughs
“🎬 Deep-dive walkthroughs, explained visually — watch now”
“Complex tech. Simple visuals. Subscribe to CoolTech M3Z”
🤝 In-Person/Online LIVE Tech Meetups
“👥 Meet. Learn. Build. Join Dublin’s top tech minds:”
Deep Learning Dublin
API Dublin